爬山算法(Hill Climbing)是一种启发式搜索算法,常用于解决优化问题。它的核心思想是从一个初始解开始,不断朝着增益最大的方向移动,直到达到局部最优解。
实现步骤
- 从初始解开始。
- 在当前解的邻域中找到一个更好的解。
- 如果找到的解比当前解好,则移动到该解,并重复步骤2。
- 如果在邻域中没有找到更好的解,则算法终止,返回当前解。
代码示例
以下示例展示了如何使用爬山算法求解一个简单的函数优化问题。目标是找到使函数值最大的输入值。
示例问题:最大化函数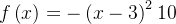
import random
def hill_climbing(f, x0, step_size=0.1, max_iterations=1000):
current_x = x0
current_f = f(current_x)
for i in range(max_iterations):
neighbors = [current_x + step_size, current_x - step_size]
next_x = max(neighbors, key=f)
next_f = f(next_x)
if next_f <= current_f:
break
current_x, current_f = next_x, next_f
return current_x, current_f
# 定义目标函数
def objective_function(x):
return -(x - 3) ** 2 + 10
# 初始解
initial_solution = random.uniform(-10, 10)
# 执行爬山算法
solution, solution_value = hill_climbing(objective_function, initial_solution)
print(f"Optimal solution: x = {solution:.4f}")
print(f"Optimal value: f(x) = {solution_value:.4f}")
案例分析
在这个案例中,我们定义了一个简单的目标函数 ,其最大值出现在 𝑥=3 处。爬山算法从随机初始解开始,通过在邻域中寻找更优解,不断更新当前解,直到达到局部最优解。输出显示了算法找到的最优解及其对应的函数值。
解释与改进
爬山算法的一个主要缺点是它容易陷入局部最优解。为了改进这一点,可以使用以下几种方法:
- 随机重启爬山算法(Random Restart Hill Climbing):多次运行爬山算法,每次从不同的随机初始解开始,最后选择最佳结果。
- 模拟退火算法(Simulated Annealing):在搜索过程中偶尔接受较差的解,以跳出局部最优解。
- 爬山算法与其他启发式搜索算法结合:例如与遗传算法(Genetic Algorithm)结合,利用全局搜索能力。
随机重启爬山算法示例
def random_restart_hill_climbing(f, num_restarts=10, step_size=0.1, max_iterations=1000):
best_solution = None
best_value = float('-inf')
for _ in range(num_restarts):
initial_solution = random.uniform(-10, 10)
solution, solution_value = hill_climbing(f, initial_solution, step_size, max_iterations)
if solution_value > best_value:
best_solution, best_value = solution, solution_value
return best_solution, best_value
# 执行随机重启爬山算法
solution, solution_value = random_restart_hill_climbing(objective_function)
print(f"Optimal solution: x = {solution:.4f}")
print(f"Optimal value: f(x) = {solution_value:.4f}")
在随机重启爬山算法中,我们多次运行标准爬山算法,每次从不同的随机初始解开始。最后,选择所有运行中找到的最佳解。这种方法可以有效地避免陷入局部最优解,提高找到全局最优解的可能性。
案例:使用爬山算法解决旅行商问题(TSP)
旅行商问题(Travelling Salesman Problem,TSP)是经典的组合优化问题,其目标是在给定的一组城市中找到一条路径,使得旅行商访问每个城市一次并返回起始城市的总距离最短。
实现步骤
- 定义问题:给定一组城市及其之间的距离矩阵。
- 初始化解:随机生成一个初始路径。
- 计算适应度:计算当前路径的总距离。
- 生成邻域解:通过交换路径中的两个城市生成邻域解。
- 选择更优解:在邻域解中找到比当前解更优的解,更新当前解。
- 重复:重复生成邻域解和选择更优解的过程,直到达到停止条件。
代码示例
import random
import itertools
# 定义距离矩阵
distance_matrix = [
[0, 2, 9, 10],
[1, 0, 6, 4],
[15, 7, 0, 8],
[6, 3, 12, 0]
]
# 计算路径总距离
def calculate_total_distance(path, distance_matrix):
total_distance = 0
for i in range(len(path)):
total_distance += distance_matrix[path[i - 1]][path[i]]
return total_distance
# 生成初始解
def generate_initial_solution(num_cities):
path = list(range(num_cities))
random.shuffle(path)
return path
# 生成邻域解
def generate_neighbors(path):
neighbors = []
for i in range(len(path)):
for j in range(i + 1, len(path)):
neighbor = path[:]
neighbor[i], neighbor[j] = neighbor[j], neighbor[i]
neighbors.append(neighbor)
return neighbors
# 爬山算法
def hill_climbing_tsp(distance_matrix, max_iterations=1000):
num_cities = len(distance_matrix)
current_solution = generate_initial_solution(num_cities)
current_distance = calculate_total_distance(current_solution, distance_matrix)
for _ in range(max_iterations):
neighbors = generate_neighbors(current_solution)
best_neighbor = min(neighbors, key=lambda p: calculate_total_distance(p, distance_matrix))
best_neighbor_distance = calculate_total_distance(best_neighbor, distance_matrix)
if best_neighbor_distance >= current_distance:
break
current_solution, current_distance = best_neighbor, best_neighbor_distance
return current_solution, current_distance
# 执行爬山算法
solution, solution_distance = hill_climbing_tsp(distance_matrix)
print(f"Optimal solution: {solution}")
print(f"Optimal distance: {solution_distance}")
案例分析
在这个案例中,我们使用爬山算法来解决一个包含4个城市的旅行商问题。我们定义了一个距离矩阵,表示城市之间的距离。爬山算法从一个随机生成的初始路径开始,通过在邻域解中寻找更优的路径,不断优化当前解,最终找到一个局部最优解。
解释与改进
爬山算法在处理TSP问题时,容易陷入局部最优解。以下是一些可能的改进:
- 随机重启爬山算法:多次运行爬山算法,每次从不同的随机初始解开始,最后选择最佳结果。
- 模拟退火算法:在搜索过程中偶尔接受较差的解,以跳出局部最优解。
- 混合算法:结合遗传算法、粒子群优化等全局搜索算法,提高找到全局最优解的可能性。
随机重启爬山算法示例
def random_restart_hill_climbing_tsp(distance_matrix, num_restarts=10, max_iterations=1000):
best_solution = None
best_distance = float('inf')
for _ in range(num_restarts):
solution, solution_distance = hill_climbing_tsp(distance_matrix, max_iterations)
if solution_distance < best_distance:
best_solution, best_distance = solution, solution_distance
return best_solution, best_distance
# 执行随机重启爬山算法
solution, solution_distance = random_restart_hill_climbing_tsp(distance_matrix)
print(f"Optimal solution: {solution}")
print(f"Optimal distance: {solution_distance}")
案例:使用爬山算法优化机器学习模型参数
爬山算法不仅可以用于组合优化问题,还可以用于优化机器学习模型的参数。下面我们展示如何使用爬山算法来优化线性回归模型的参数。
实现步骤
- 定义问题:给定一组数据和一个线性回归模型,优化模型的参数以最小化损失函数(例如均方误差)。
- 初始化解:随机生成初始模型参数。
- 计算适应度:计算当前参数下的损失函数值。
- 生成邻域解:通过在当前参数周围进行微小扰动生成邻域解。
- 选择更优解:在邻域解中找到比当前解更优的解,更新当前解。
- 重复:重复生成邻域解和选择更优解的过程,直到达到停止条件。
代码示例
import numpy as np
# 生成数据
np.random.seed(0)
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
# 定义损失函数(均方误差)
def mse(theta, X, y):
m = len(y)
predictions = X.dot(theta)
return (1/m) * np.sum((predictions - y) ** 2)
# 爬山算法优化线性回归参数
def hill_climbing_lr(X, y, initial_theta, step_size=0.01, max_iterations=1000):
current_theta = initial_theta
current_loss = mse(current_theta, X, y)
for i in range(max_iterations):
neighbors = [current_theta + step_size * np.random.randn(*current_theta.shape) for _ in range(10)]
best_neighbor = min(neighbors, key=lambda t: mse(t, X, y))
best_neighbor_loss = mse(best_neighbor, X, y)
if best_neighbor_loss >= current_loss:
break
current_theta, current_loss = best_neighbor, best_neighbor_loss
return current_theta, current_loss
# 初始化参数
initial_theta = np.random.randn(2, 1)
# 扩展X矩阵,以包含偏置项
X_b = np.c_[np.ones((100, 1)), X]
# 执行爬山算法
solution_theta, solution_loss = hill_climbing_lr(X_b, y, initial_theta)
print(f"Optimal theta: {solution_theta.ravel()}")
print(f"Optimal loss: {solution_loss}")
案例分析
在这个案例中,我们使用爬山算法来优化线性回归模型的参数。数据由线性模型生成,并添加了一些随机噪声。爬山算法从随机初始化的参数开始,通过在参数空间中搜索最优解,最小化损失函数(均方误差)。
解释与改进
爬山算法在优化模型参数时可能会陷入局部最优解。以下是一些可能的改进:
- 随机重启爬山算法:多次运行爬山算法,每次从不同的随机初始解开始,最后选择最佳结果。
- 模拟退火算法:在搜索过程中偶尔接受较差的解,以跳出局部最优解。
- 梯度下降:使用梯度信息更高效地找到最优解。
随机重启爬山算法示例
def random_restart_hill_climbing_lr(X, y, num_restarts=10, step_size=0.01, max_iterations=1000):
best_theta = None
best_loss = float('inf')
for _ in range(num_restarts):
initial_theta = np.random.randn(2, 1)
theta, loss = hill_climbing_lr(X, y, initial_theta, step_size, max_iterations)
if loss < best_loss:
best_theta, best_loss = theta, loss
return best_theta, best_loss
# 执行随机重启爬山算法
solution_theta, solution_loss = random_restart_hill_climbing_lr(X_b, y)
print(f"Optimal theta: {solution_theta.ravel()}")
print(f"Optimal loss: {solution_loss}")
通过随机重启爬山算法,我们多次运行爬山算法,每次从不同的随机初始解开始。通过多次尝试,算法可以有效避免陷入局部最优解,提高找到全局最优解的概率。